Overview
Open RAN (O-RAN) designs an intelligent network controller (RAN Intelligent Controller, RIC) for supporting more efficient and (non-) real-time control of the Radio Access Network (RAN). To achieve this goal, O-RAN formulates a series of specifications for its computing architecture and provides optimal designs for different applications and different types of algorithms. O-RAN's architecture delineates a multitude of interfaces, each embodying distinct facets of RAN operations. For example, A1 Interface is a pivotal interface in the O-RAN ecosystem. A1 facilitates a connection between non-RT RIC and Near-RT RIC. Its primary role is to harness policy-driven guidance, reflecting the architecture's emphasis on adaptability. On the other hand, E2 Interface acts as the bridge between the Near-RT RIC and entities such as O-CU-CPs, O-CU-UPs, and O-DUs. The A1 and E2 interfaces demonstract a part of modular design in O-RAN.
Zero-Shot Learning (ZSL)
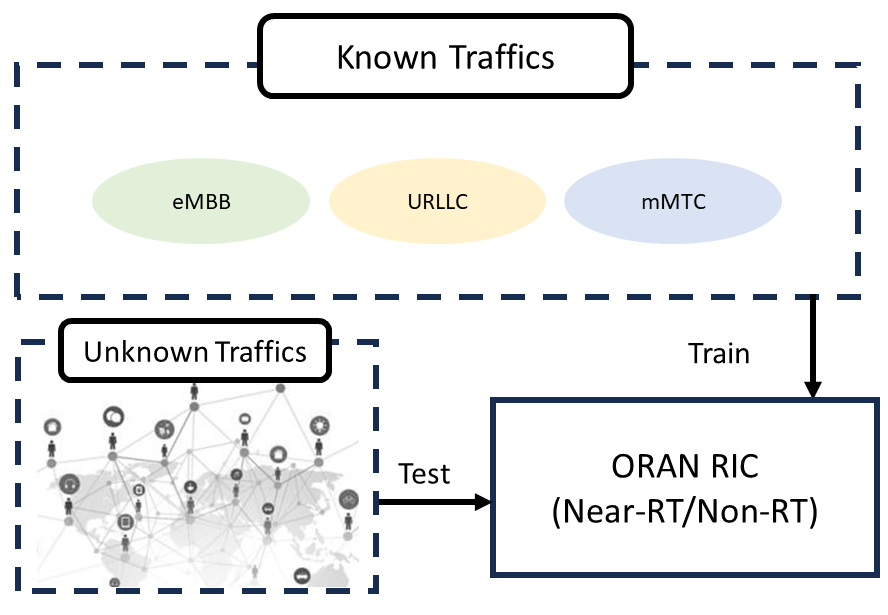
In the era of 5G and beyond, O-RAN RIC (Open Radio Access Network RAN Intelligent Controller) faces a daunting challenge: how to train Artificial Intelligence/Machine Learning (AI/ML) models without real datasets. The scarcity of such datasets arises from multifaceted issues including strict privacy guidelines, stringent regulatory constraints, commercial sensitivities, and the multifaceted intricacy of the Radio Access Network (RAN).
To navigate this complex landscape, the concept of Zero-Shot Learning (ZSL) emerges as a beacon of hope. ZSL is a machine learning paradigm where a model is trained on one set of classes but is then asked to recognize objects from unseen classes. In the context of O-RAN RIC, this translates to training on one set of network conditions (like URLLC - Ultra Reliable Low Latency Communications, eMBB - enhanced Mobile Broadband, and mMTC - massive Machine Type Communications) and then testing the model under entirely different, previously unseen network scenarios.
There are three methods that leverage ZSL to train AI/ML models in O-RAN RIC:
1) O-RAN Simulator: An avant-garde open-source platform that furnishes a realistic RAN simulation environment. This simulator lets a reinforcement learning agent immerse, make decisions, and consequently acquire optimal policies, all while being under the aegis of a controlled environment.
2) O-RAN Digital Twin: This digital counterpart provides a precise virtual depiction of the RAN. It's not just a mirror reflection but a dynamic model that lets agents derive policies which align seamlessly with the real network's idiosyncrasies.
3) Generative Data: Treading a different path, this method crafts synthetic data that mirrors genuine network data. Not only does this preserve the sanctity of privacy, but it also allows the Deep Reinforcement Learning (DRL) agent to imbibe from a plethora of diverse scenarios.
In conclusion, using ZSL with these avant-garde methods is revolutionizing the way we approach AI/ML training in O-RAN RIC. Despite the absence of real datasets, these approaches adeptly circumvent issues of privacy, commercial sensitivities, and the labyrinthine complexity intrinsic to RAN, paving the way for a more robust and resilient network future.
Reference